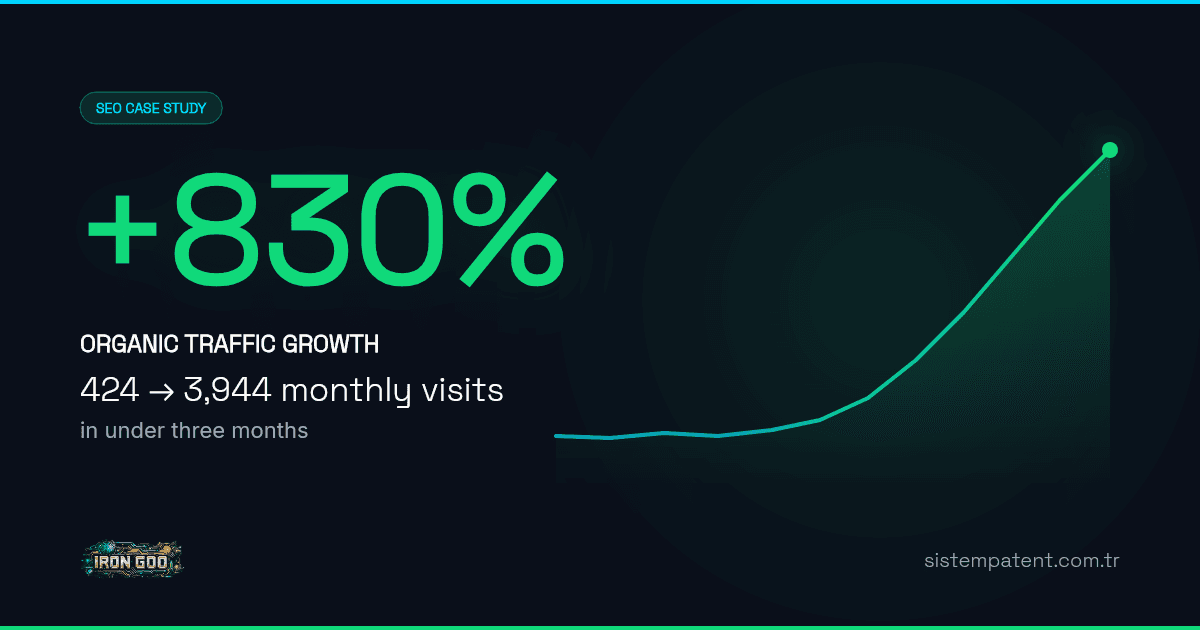
Rebuilding sistempatent.com.tr: 830% Organic Traffic Growth in Under Three Months
Background
Sistem Patent is one of Türkiye's longest-running intellectual-property registration firms, operating since 1999. Our flagship site at sistempatent.com.tr is the primary channel for trademark, patent, design, and IP-protection inquiries, both from domestic Turkish businesses and from international clients seeking IP coverage in Türkiye.
In 2026 we completed a full rebuild of the site on a modern Next.js + Payload CMS stack. The rebuild was triggered by a multi-year decline in organic acquisition that we eventually traced to a series of compounding technical-SEO failures introduced during an earlier WordPress migration. This case study is a candid post-mortem and recovery playbook.
The short version of the outcome: in the three months after the work began, estimated monthly organic traffic went from 424 to 3,944, an 830% increase. The full numbers and the traffic curve are in the results section at the end. This is how we got there.
We do not sell SEO services. We are publishing this because the lessons are general, and because most of the mistakes we made are mistakes we still see other Turkish service businesses making today.
Where we started: a 20-year SEO history compressed into three platforms
The ASPX era (~2008 – mid-2010s)
The original site was a hand-built ASPX / IIS application, typical of late-2000s Turkish corporate web work. It was not architecturally beautiful, but it had earned three valuable SEO assets over a decade:
- A deep URL footprint of roughly 144 indexed
.aspxURLs covering long-tail procedural queries, trademark application steps, sector-specific patent guidance, opposition-period explanations. These ranked because they were often the only Turkish-language answers on the open web. - A trilingual experience, Turkish, English, and German, serving international inventors and brand owners who needed IP protection in Türkiye.
- Hard-earned backlinks from law-firm blogs, university IP-law course pages, business directories, and trade associations, all pointing at specific
.aspxURLs.
The WordPress era (mid-2010s – early 2026)
At some point the site was rebuilt in WordPress. The new theme looked more current, the editorial workflow was friendlier, and on a UX-only assessment the migration was a success.
On a technical-SEO assessment, it was a disaster, for reasons we will go through one by one.
The Next.js + Payload era (2026 – present)
The current site is a custom build on Next.js 16 (React-based, server-rendered), Payload v3 (TypeScript-native headless CMS), and PostgreSQL, running on a single VPS behind Cloudflare. Everything described in the "Execution" section below refers to this platform.
The audit: what was actually wrong
Before touching code we ran a full technical-SEO audit, combining Search Console data, fresh crawls, server log archives, and a Wayback Machine sweep. The findings clustered into seven structural problems.
1. Catastrophic 301 redirect failure from the ASPX migration
When the ASPX site was decommissioned, none of the legacy URLs were redirected to their WordPress equivalents. There was no .htaccess map, no IIS rewrite rules, no central redirect table. Old URLs just started returning 404s.
This is the single most damaging mistake a CMS migration can make. By our own audit, roughly 29% of the historical organic traffic was bleeding through dead legacy URLs every single month, for years. Backlinks earned over a decade pointed at 404s. Google had reassigned most of the ranking equity to competitors.
2. Multilingual experience silently dropped
The WordPress build shipped Turkish-only. The English and German sections were not migrated and were not redirected, breaking the international acquisition channel entirely. There were no hreflang annotations anywhere on the site.
3. Cross-domain content moves with no redirect chain
Over the years, several content clusters, most notably ISO/TSE certifications and helal certification, had been moved to sister properties (sistempatent.com, eurocert.com.tr) without any redirect bridge from the originating URLs. Of the 144 "live" WordPress URLs in our inventory, only 74 actually returned 200. The other 70 were 404s pointing into the void.
4. Core Web Vitals failing on mobile
Mobile Lighthouse Performance scores on most service pages ranged from the high 50s to the high 60s. LCP was routinely over 4 seconds on a mid-tier mobile connection. Layout shift from late-loading hero images and ad/chat widgets was visible to the naked eye.
5. Structured data absent or wrong
The WordPress site emitted minimal JSON-LD. There was no Organization schema, no Service schema on the service pages, no FAQPage schema on the (extensive) FAQ section, no BreadcrumbList anywhere. Rich results that should have been baseline weren't even on the table.
6. On-page SEO drift
Across roughly 290 pages we found: ~80 services with missing or duplicate meta descriptions, ~30 pages with <title> longer than 70 characters (truncated in SERPs), ~15 pages where the H1 was a stock image alt-text, and dozens of pages where the canonical tag pointed at a staging hostname rather than the production domain.
7. No control over crawl budget or AI-bot policy
robots.txt was the default WordPress file. The XML sitemap was generated by a plugin that included draft pages and excluded a third of the live ones. Modern AI crawlers (GPTBot, ClaudeBot, Perplexity, Google-Extended) were blocked by default, cutting us off from a meaningful and growing source of qualified inbound traffic from LLM-driven search.
Strategy
We made a deliberate call not to fix any of this on the existing WordPress installation. Every patch would have been fighting the platform rather than fixing the underlying problem. Instead we rebuilt on a stack where every one of the seven failure modes above was either structurally impossible or trivially correct by default.
The priority order at launch:
- Preserve every shred of remaining link equity through a complete 301 map back to the ASPX era.
- Get the technical foundation right on day one, performance, structured data, crawl control, canonicalization.
- Restore the multilingual experience properly, not as a plugin, as a first-class architectural feature.
- Then, and only then, improve content.
Execution
Technical foundation: why Next.js + Payload over WordPress
This decision deserves its own paragraph because it is the most common question we get asked.
We picked Next.js for the front end and Payload v3 as the headless CMS for these specific SEO-relevant reasons:
- Server-rendered HTML by default, with static and incremental-static generation for content pages. Google crawls the rendered HTML directly, no client-side rendering gotchas, no JavaScript-required indexing risk.
- Native i18n routing. Turkish at
/, English at/en/, German at/de/, with locale-aware metadata, canonical URLs, and hreflang generation at the framework level. No multilingual plugin marketplace to wade through. - Image optimization built in.
next/imageships WebP and AVIF with automatic responsive sizing and lazy loading. LCP improvements are essentially free. - Full programmatic control over the
<head>. Title, description, canonical, OpenGraph, Twitter, hreflang, JSON-LD, all generated in code from the source content, with no plugin in between. - Type-safe content model. Payload's collections compile to TypeScript types consumed by the front end. Editorial changes that would break a page fail at build time rather than in production.
- No PHP runtime, no plugin sprawl, no CVE treadmill. The attack surface and the maintenance overhead both shrink dramatically.
We did not pick this stack to be fashionable. We picked it because every line item on our seven-point audit had a clean architectural answer in this stack and a workaround-shaped answer in WordPress.
The 301 redirect cleanup we should have done ten years ago
This was treated as a launch-blocking deliverable, not a "phase 2" cleanup.
We built a master URL inventory of every URL Google had ever indexed for the domain, pulled from Search Console history, archived server logs, a full fresh crawl, and a Wayback Machine sweep. The result was 289 historically interesting URLs, including the 144 legacy ASPX paths that had been 404ing for years and the 70 broken WordPress URLs we'd identified in the audit.
We mapped each one to its current canonical destination on the new site and shipped over 200 server-side 301 redirects, including cross-domain redirects for content that had legitimately moved to sister properties.
Every redirect is a single-hop 301, no chains, no 302s, no meta refreshes. We verified this with a crawl after launch.
Within weeks, Search Console showed the legacy URLs being recrawled and dropping out of the index in favor of the new canonical equivalents. Backlinks that had been pointing at dead URLs for a decade started passing equity to live pages again.
Information architecture and URL strategy
We took the opportunity to flatten and clarify the URL structure:
- Service pages live at
/<service-slug>(e.g./marka-tescili,/patent-tescili), with English at/en/<service-slug>and German at/de/<service-slug>, each locale using its own translated slug, not a numeric ID or a Turkish slug under an/en/prefix. - Office/contact pages were consolidated under
/iletisim/<office-slug>with 301s from the previous flat structure. - Blog posts at
/blog/<slug>with paginated/blog?page=Nand properrel="prev"/rel="next"linking. - FAQ section restructured into 2 top-level categories with 12 sub-categories, served at
/sik-sorulanlar/<category>/<sub-category>, with FAQ detail pages indexable individually. 64 legacy/sik-sorulanlar-kategori/*URLs all 301'd to their new canonical homes. - Search routes, faceted parameter URLs, and admin paths explicitly excluded from indexing via
robots.txtandnoindexheaders, preserving crawl budget for the pages that actually matter.
Core Web Vitals: from the 60s to the 90s on mobile
After the rebuild, mobile Lighthouse Performance scores on the same service pages consistently land in the low- to mid-90s, with desktop scores in the upper 90s. Specific changes that contributed:
- Server-side rendering with HTML streaming, so the LCP element ships in the initial response.
next/imagefor every above-the-fold image, with explicitwidth/heightto eliminate cumulative layout shift.- Critical CSS inlined automatically by Next.js, with the rest deferred.
- Tailwind v4 for the design system, utility-class CSS that ships only the styles actually used on a given page (we shaved roughly 60% off our previous CSS payload).
- Third-party scripts deferred, Google Tag Manager, Tawk.to chat, Meta Pixel all load post-interactive and behind a KVKK consent gate.
- Self-hosted Inter font with
font-display: swapand a preload hint on the400weight. - HTTP/2 over Cloudflare with proper cache-control headers on static assets (1-year immutable).
- Brotli compression on every text response.
LCP on a mid-tier 4G mobile connection now lands consistently under 2 seconds on landing pages and under 2.5 seconds on the deepest service pages.
Structured data: complete coverage, generated from source
Every page on the new site ships rich JSON-LD automatically:
Organizationschema site-wide in the root layout, withsameAspointing at our verified social profiles,addresswith multiplePostalAddressentries for our offices, andcontactPointentries per office.Serviceschema on every service page (87+ services), withprovider,areaServed: "Türkiye", andserviceType.FAQPageschema on every FAQ page and on the FAQ index, 161 FAQs in total, all rich-result eligible.Articleschema on every blog post withheadline,image,datePublished,dateModified, andauthor.BreadcrumbListon every internal page.LocalBusinessschema on every office page, with geo coordinates.
None of this is plugin-emitted. All of it is generated from the source content at render time, which means it cannot drift out of sync with the visible page.
Multilingual SEO: restoring (and properly engineering) Turkish, English, and German
The trilingual experience that was lost in the WordPress migration is back, this time engineered to current standards rather than bolted on.
- Field-level localization in Payload, editors localize individual fields (title, body, meta description, slug) rather than duplicating entire pages, which keeps the content graph clean.
- Per-locale URL slugs in every language,
/en/trademark-registration,/de/markenanmeldung, not Turkish slugs under language prefixes. hreflangannotations on every localized page, declaring the TR / EN / DE counterparts plusx-default, with both<link rel="alternate">tags in the<head>andxhtml:linkalternates in a split sitemap.- Per-locale canonical URLs so each language version is canonical to itself.
- A locale-aware language switcher that performs a full navigation rather than a client-side route change, ensuring server-rendered chrome (footer,
<html lang>) refreshes correctly.
On the content side: the archived ASPX EN/DE pages from the Wayback Machine turned out to be thin, partial, and dated. Most of the Turkish content had no archived translation at all. We rebuilt the entire English and German corpora from scratch, roughly 290 pages per language, to native IP-law register. This was the single most significant content investment in the rebuild and was worth every lira. The new EN/DE content reads like a competent IP firm speaking to a sophisticated international audience, which is exactly the brand we project to European inventors.
AEO: optimizing for LLM-driven search
A meaningful and growing share of qualified inbound traffic now comes from AI-driven search, ChatGPT, Claude, Perplexity, Google's AI Overviews. We treat Agentic Engine Optimization as a separate workstream alongside classical SEO.
Practical changes:
robots.txtexplicitly allows GPTBot, ClaudeBot, CCBot, Google-Extended, and PerplexityBot. Blocking these by default, which is what most CMSs do, cuts you out of the answer-engine surface entirely.- Content is structured for quotability, short, declarative answer paragraphs at the top of every guide page, with the longer explanation underneath. LLMs preferentially cite the concise framing.
- Heavy investment in FAQ content with explicit question-and-answer structure and
FAQPageschema, which is high-impact for AI-citation eligibility. - Authorship and entity signals,
Organizationschema with consistent NAP across every office page and external profile, so LLMs can confidently identify "Sistem Patent" as the entity behind the content. - Clean, semantic HTML with proper heading hierarchy, since LLM crawlers depend on document structure more than rendered visual layout.
On-page SEO sweep
We audited and rewrote on-page elements across the site:
- 96 service-page meta descriptions normalized, trimmed long ones to under 170 characters at word boundaries, padded short ones above 120 characters with branded calls-to-action, generated missing ones from the page title.
- Title-tag template standardized to
"%s - Sistem Patent", with bespoke absolute titles on top-priority commercial pages (homepage,/marka-tescili,/patent-tescili,/marka-sorgula). - Duplicate brand suffixes stripped from a dozen pages whose titles had read
"... - Sistem Patent | Sistem Patent". - Canonical URLs site-wide, hardcoded to
https://sistempatent.com.trvia a singleCANONICAL_ORIGINhelper, eliminating staging-host leakage. og:imageandtwitter:imagerouted through the same helper, fixing broken social-share previews that had persisted from the WordPress era.- Internal linking densified, every service page links to its parent category landing page, its sibling services, and 3–5 contextually relevant FAQs.
- Image
altattributes populated meaningfully from a content audit rather than left as filenames.
Crawl, index, and sitemap control
- Modern
robots.txtexplicitly allowing AI crawlers, blocking/admin,/api/,/search, and parameterized URLs. - Programmatic XML sitemap generated by Next.js from the published-content state, refreshed every 5 minutes, with
_status: 'published'filtering so drafts never leak. Submitted to Google Search Console and Bing Webmaster. - Per-locale sitemap entries with
xhtml:linkalternates declaring the TR/EN/DE counterparts. - No-index headers on staging environments, faceted search pages, and internal admin routes, but never on production content pages (this is a common WordPress plugin foot-gun we explicitly guarded against).
Forms, conversion plumbing, and analytics
A rebuild is a chance to align measurement with how the business actually works:
- Single
ContactFormcomponent reused across every public touchpoint, homepage, service pages, FAQ pages, office pages, with consistent KVKK consent capture in the message body itself (a Turkish privacy-law requirement we made unavoidable rather than optional). - Phone field required on every public form, reflecting the phone-first sales motion our team actually runs.
- Source tagging, every submission carries
sourceand (where relevant)sectorfields so we can attribute leads back to the specific page and offering. - GA4, Google Tag Manager, and Meta Pixel wired in, all consent-gated through a single KVKK-compliant cookie banner.
- Resend for transactional email with proper SPF and DKIM records on a dedicated
send.subdomain, preserving the main-domain Yandex MX records untouched.
Specific bugs worth documenting (because we see them on other sites all the time)
A few of the issues we hit and fixed are worth flagging publicly:
- Next.js i18n requires
dynamic = 'force-dynamic'on every/en/*page when the layout reads the locale from request headers. Otherwise the layout snapshots the default-locale chrome (<html lang>, footer, etc.) into the static HTML at build time. This is invisible to TypeScript and to the build process; we caught it only by render-time crawl. - Server actions can carry module-scope locale bindings that leak Turkish copy into English / German submission flows. The only way to catch this is to submit forms in a non-default locale and crawl the result.
- Em-dashes and corporate filler in marketing copy survive editorial review because nobody is looking for them. We sweep rendered output for em-dashes and a wordlist of overused filler (
leverage,utilize,seamless,robust) every release. - Turkish diacritics leaking into English content (
İ,ş,ğ) silently break CSStext-transform: uppercaseand look unprofessional. A normalization pass and a regex audit script are now part of CI. - Canonical URL helpers must be the single source of truth. Without one, you will eventually emit a
og:imagepointing at your staging server, and you will not notice until someone shares your page on LinkedIn.
Results: from 424 to 3,944 monthly organic visits
When we first published this post we held the traffic numbers back, on principle, until the new site had been through a full Google reindexing cycle (typically 6–12 weeks after a redirect-heavy migration). That cycle is now behind us. Here is the follow-up we promised.
In the three months from March to early June 2026, estimated monthly organic traffic to sistempatent.com.tr grew from 424 to 3,944 visits. That is an 830% increase, roughly 9.3 times the traffic we started with, and it happened in under three months.
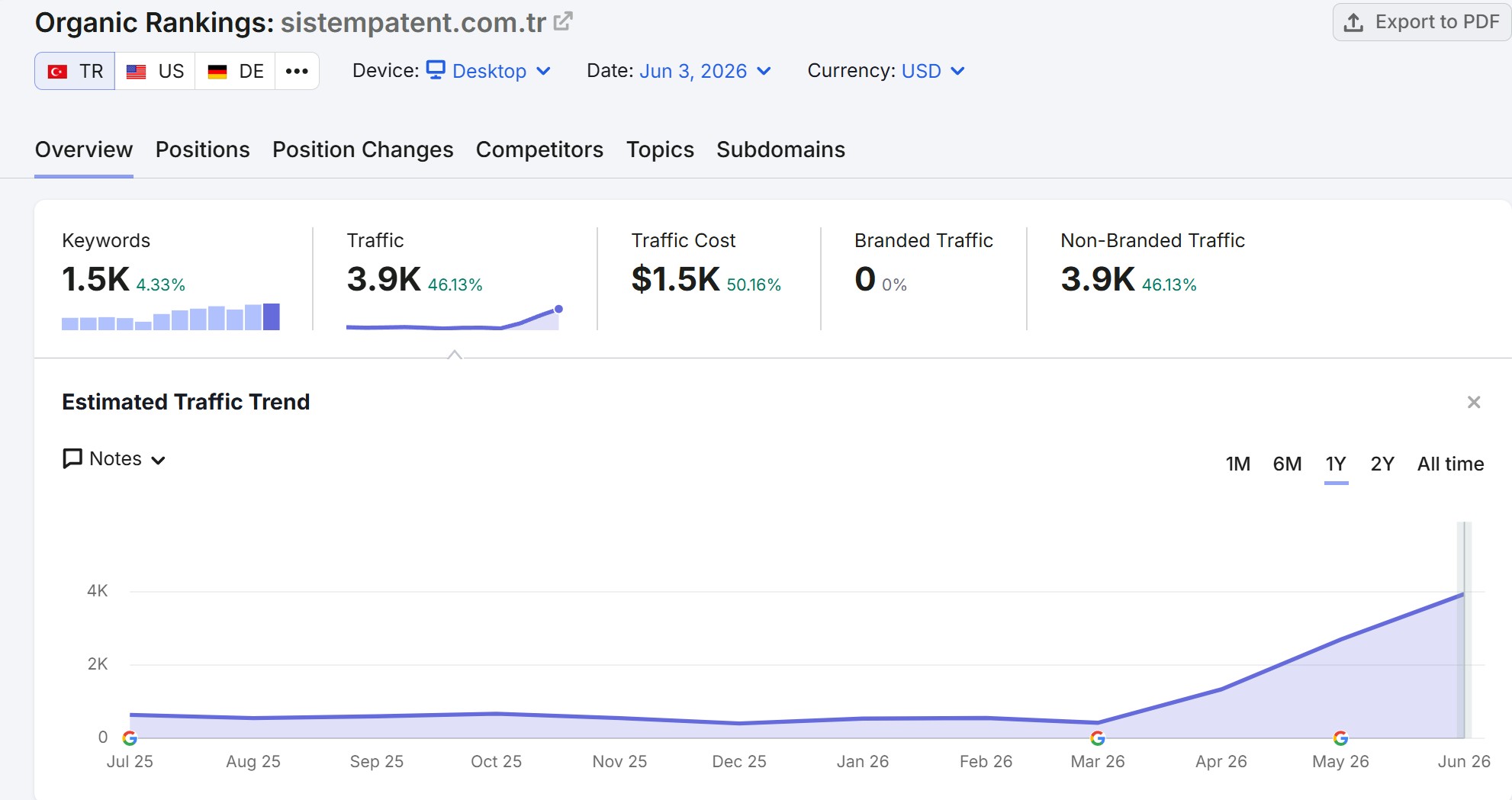
Estimated organic traffic, July 2025 to June 2026. The line sits flat near 400 monthly visits for most of the year, then inflects in March 2026, the month the rebuild and SEO work began, and climbs to 3,944 by early June. Source: Semrush.
The curve is the whole story. For most of the prior year the site held flat at a few hundred monthly visits, the steady state of a WordPress install quietly leaking its own history through dead URLs. The inflection point lines up precisely with the work described above: the 301 recovery reconnected a decade of backlinks to live pages, the trilingual rebuild made the English and German catalogue indexable for the first time in years, and the technical and AEO foundation let Google, and the AI crawlers, re-evaluate the domain from a clean baseline.
A few things worth noting about the shape of this recovery:
- It is overwhelmingly non-branded traffic. Branded search for the firm's own name was always going to find the site. This growth is in non-branded, intent-driven queries, the trademark, patent, and IP-procedure searches that represent genuine new demand.
- It compounds rather than spikes. A redirect-and-reindex recovery is not a one-off bump. Equity that had been thrown away every month for years is now being retained, and the restored trilingual surface keeps earning impressions for queries it could not reach at all before.
- The launch-day technical wins held. Everything we shipped at cutover is still in place and still measurable:
- The site renders the same content in roughly one-third the time it took on WordPress.
- Every legacy ASPX and WordPress URL that previously 404'd now returns a single-hop 301 to a live canonical destination.
- Trilingual coverage is complete across TR, EN, and DE, with full hreflang and per-locale canonicalization.
- Structured-data coverage is at 100% across the service, FAQ, blog, and office page templates.
- Indexable surface area has roughly tripled, largely because the multilingual content is now indexable rather than non-existent.
- AI-crawler accessibility is full-allow rather than the WordPress default of full-block.
Three months is the beginning of a recovery curve like this, not the end of it, and we will keep tracking it. But the thing we were unwilling to promise at launch, that the rebuild would actually move traffic and not just tidy up the architecture, is now on the record.
Lessons we would give to anyone doing a similar rebuild
- A CMS migration without a complete 301 redirect map is malpractice. Treat the redirect inventory as a launch blocker, not a follow-up task. Pull every URL Google has ever indexed, map each one, and verify single-hop 301s with a post-launch crawl.
- Multilingual content is not a "phase 2" feature. If your previous site had it, your new site needs it on day one, with per-locale slugs and proper hreflang from launch.
- SEO is architecture, not plugins. Canonical tags, hreflang, structured data, sitemap behavior, all belong in code you control. Plugins drift, abandon, and break.
- Performance is now a ranking and a conversion factor. A site scoring 95 on mobile Lighthouse measurably outperforms a 65, and Google notices both.
- AEO is the next compounding investment. Allow the major AI crawlers, structure your content for quotability, and double down on FAQ schema. The cost is near zero and the traffic curve is still climbing.
- Audit what you actually publish, not what your CMS says you publish. Render-time crawls catch a category of bugs (locale leaks, diacritic mangling, hardcoded staging URLs, missing canonicals) that no amount of staging-environment testing will surface.
- Don't undervalue content quality in your non-domestic languages. For an international service business, native-grade EN/DE content is the highest-impact SEO investment available, and a cheap substitute is always worse than you expect.
Where the site is now
sistempatent.com.tr is live on Next.js + Payload, fully trilingual, with a clean URL structure, a complete 301 map back to the ASPX era, modern Core Web Vitals, full structured-data coverage, AI-crawler-friendly indexing controls, and an editorial workflow that lets our team publish updates in minutes rather than hours.
If you are planning a similar rebuild and would like to compare notes, our door is open.